

DeepSeek представила модели искусственного интеллекта, конкурирующие с OpenAI

Компания DeepSeek анонсировала свои новые модели искусственного интеллекта — DeepSeek-R1 и DeepSeek-R1-Zero, которые способны решать сложные задачи, требующие аналитического мышления. Модель DeepSeek-R1-Zero была обучена исключительно с использованием обучения с подкреплением (RL), что позволило ей самостоятельно развить такие способности, как самопроверка, рефлексия и построение сложных цепочек рассуждений (CoT).
«Это первое открытое исследование, которое подтверждает, что способности к рассуждению у языковых моделей могут быть стимулированы исключительно через RL, без необходимости предварительного обучения на размеченных данных», — пояснили исследователи DeepSeek.
Однако у DeepSeek-R1-Zero есть и ограничения, такие как склонность к бесконечному повторению, низкая читаемость и смешение языков. Для устранения этих недостатков была разработана модель DeepSeek-R1, которая использует дополнительные данные для предварительного обучения перед этапом RL. Это позволило значительно улучшить её производительность.
Сравнение с конкурентами
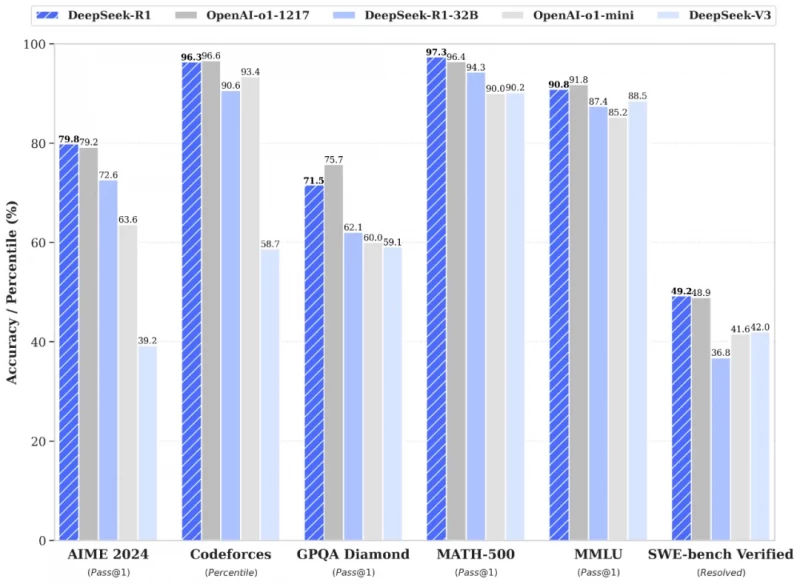
DeepSeek-R1 демонстрирует результаты, сопоставимые с моделью OpenAI o1, в таких задачах, как математика, программирование и общие рассуждения. Например, на тесте MATH-500 (Pass@1) DeepSeek-R1 достиг показателя 97,3%, что выше, чем у OpenAI (96,4%). Модель DeepSeek-R1-Distill-Qwen-32B, созданная на основе дистилляции, показала выдающиеся результаты на тесте LiveCodeBench (Pass@1-COT) с результатом 57,2%.
Польза для индустрии
DeepSeek также поделилась подробностями своего подхода к разработке моделей, который включает два этапа обучения на размеченных данных (SFT) и два этапа RL. Этот метод позволяет не только улучшить базовые способности модели, но и адаптировать её к предпочтениям человека.
«Мы уверены, что наш подход принесёт пользу индустрии, создавая более совершенные модели», — заявили в компании.
Дистилляция как ключевой элемент
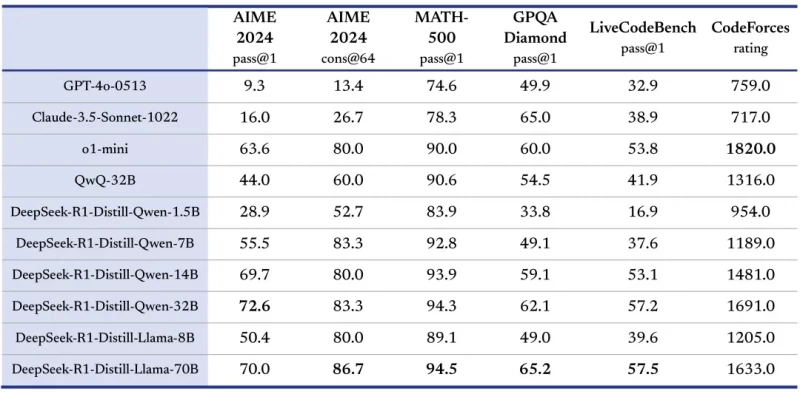
Особое внимание DeepSeek уделила процессу дистилляции, который позволяет передавать способности к рассуждению от крупных моделей к более компактным. Например, модели с 1,5 миллиардами параметров демонстрируют результаты, сопоставимые с более крупными аналогами.
Все модели DeepSeek-R1 и их дистиллированные версии доступны под лицензией MIT, что позволяет использовать их в коммерческих целях и модифицировать. Однако пользователи должны учитывать лицензии базовых моделей, таких как Apache 2.0 и Llama3.